Reinforcement Learning
Last Updated 21 Apr 2023The project as presented at university:
Motivation behind the role:
Each year millions of people suffer from addictive behaviours. This reduces their quality of life and has wider societal impacts, costing the economy and contributing to climate change.
Consequently, tackling addictions is a high-priority goal for neuroscience, however, until this point, research focused primarily on substance use disorders. This is unfortunate, with behavioural addictions such as pathological gambling, gaming and social media addiction becoming increasingly problematic.
Therefore, the goal of this research was to build on existing research to create a novel reinforcement learning algorithm that could accurately capture both substance use disorders and behavioural addictions.
Hopefully, future models such as this one can be used to mitigate risk factors and prevent addictions from arising. They could influence treatments for addiction, improving the quality of life of afflicted individuals, and their loved ones and helping reduce broader societal issues.
The solution:

To create a simulation capturing dopamine-mediated addictions, the project’s dual-process model consisted of a model-free component. This replicated habitual behaviours, which using a variation on Q-learning enabled based on the following two papers:
- Redish (2004) - Addiction as a computational process gone awry
- Dezfouli (2009) - A neurocomputational model for cocaine addiction
The model-free component could capture the uptake and maintenance of addiction, with sub-optimal addictive actions being chosen over better ones. This was vital, providing a foundation that mirrored experimental findings and could be further built upon to also capture behavioural addictions.

Doing so involved introducing a model-based component. This enabled the agents to plan and demonstrate more complex behaviours such as relapse. Crucially, it also let the dual-process model move beyond addictions purely as a result of a ‘non-compensable drug-based reward’ which was key to the purely model-free approaches. Ultimately, the dual-process model captures behavioural addictions as well as substance use disorders. As with the model-free behaviours, these ideas were based on existing research:
- Redish (2007) - Reconciling reinforcement learning models with behavioural extinction and renewal: implications for addiction, relapse, and problem gambling
- Pettine (2023) - Human generalization of internal representations through prototype learning with goal-directed attention

Pettine’s 2023 paper was a critical component of the finalised design, using latent states to create internal representations of the current state. This caused the agents to predict its state based on its context, rather than being provided with this information.
The stimuli in each of the world states could change to reflect variation in the rewards seen, implicitly influencing the agent’s behaviour. Consequently, the agent could internally view the same world state as multiple different states.
This created the opportunity for gambling addictions to arise, with losses being assigned to one state, but the agent always chasing the possibility of moving into the highly rewarding winning state.
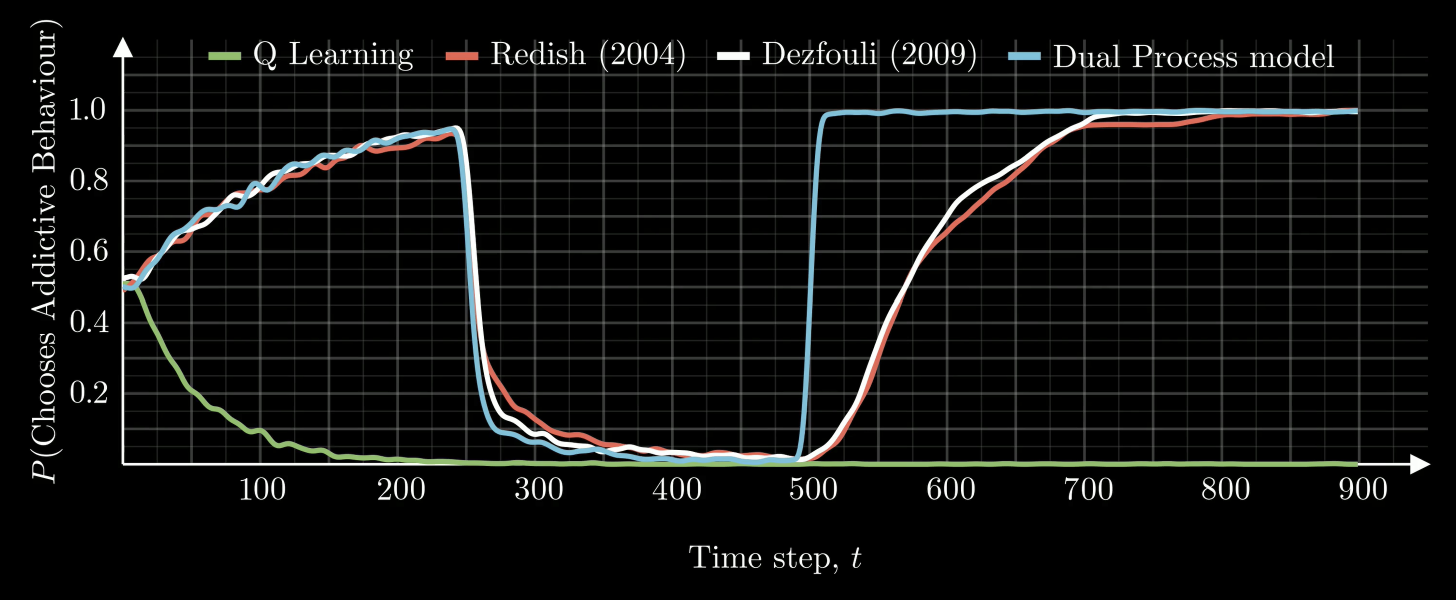
Furthermore, it allowed relapse to be simulated (see above). Model-free solutions need to unlearn the addiction during periods of recovery, meaning re-exposure and the initial exposure cause addictive choices to be preferred at the same speed. Conversely, with the model free component cestation leads to additional states being learned. This means when the addictive stimulus is shown the agent moves back to the previously learned internal state, suddenly relapsing and reflecting real-world behaviour more closely.
Technology used
The project used the Python OpenAI Gym package to create all environments and agents, with training being done locally. This was because no deep learning technologies were used, meaning there wasn’t a need to use cloud providers.


Agents and environments were designed in an object-oriented way so the project could exploit inheritance and polymorphism. This reflected how the research built upon each other and simplified the evaluation by using the same code for each instance.
The full report
If you’re particularly interested the full (63-page!) report is available to read at georgegrainger.com/rl-project.pdf.